The core part of Bitcoin mining is performing a double SHA-256 hash digest and comparing the result against the target. Two years ago, in 2013, the first Bitcoin ASIC miners appeared on the market. Since then, mining ASIC technology advanced both in terms of the manufacturing technology (the node) and in terms of design, to achieve greater hashing rates, lower power consumption and lower cost. ASIC miners are now being designed and manufactured for the 16 nm CMOS semiconductor device fabrication process. However not much is known about the design optimizations and trade-offs each company has applied to the design in order to be competitive. That information is probably confidential. For the all of us not directly employed in the Bitcoin ASIC industry I found these three papers that may serve as starting points of a SHA-256 ASIC design. These papers propose several optimization techniques such as pipelining, delay balancing, loop unrolling, the use of Carry-Save adders (CSA), Carry-Lookahead Adders (CLA), and Hierarchical CLA. Nevertheless, is seems that there after 2 years of advances there is little room to improve Bitcoin ASIC designs and so the industry will reach the same limits as state-of-the-art microprocessor manufacturing and further improvements will rely solely on Moore’s law. But this is false. Maybe the majority of the Bitcoin mining industry is making the false assumption that Bitcoin mining relates to computing a cryptographic hash function of a message. Cryptography is based on number theory, where there is no room for computing errors. In many cryptographic schemes, such as in digital signatures, hardware faults that end up with the generation of incorrect signatures may fully compromise the security of the private keys. There are several attack techniques that exploit this extreme reliance of cryptography on accurate computing in order to steal secrets. Standard public key cryptography is also based on number theory, and so there is little room for mathematical approximations, nor tolerance for faults in computation. But Bitcoin mining is a trial and error procedure: computations that do not lead to a block solution are discarded. Once a block solution is found, the solution is generally verified by software, firmware or hardware to check its correctness, so a small failure rate in the hardware does not lead to any catastrophic money loss. Hardware failures, at controlled rates, does not pose any risk to mining.
When approximation works
Because of the confusion and diffusion properties of the SHA-256 hash function, the intermediate values, the SHA-256 state, tend to behave as a uniform random variable: algebraic relations within the inputs are destroyed and statistical bias is reduced after each SHA-256 round. Because of this, an approximate adder that deterministically fails on some simple additions (such as 0xFFFFFFFF+1) does not pose any particular risk.
In computing, higher hardware failures are a trade-off for lower power consumption, higher clock rate, a reduced number of logic gates in circuits or shorter critical delays in circuits. In SHA-256 miners, the most components that consume the higher area are adders, often implemented as CLAs to reduce the critical propagation delay. Also the number of additions performed is low compared with the number of additions required in mining scrypt based cryptocurrencies like Litecoin. A canonical SHA-256 round design, as proposed by Dadda et al. would use 3 CLAs (and 8 CSA) in each round, so a full double SHA-256 core would perform 384 CLA additions. What if we replace each adder by an approximate adder, allowing a controlled failure rate, so that the total probability of failure is still kept small?
A candidate that stands out for approximation for which we can control the failure rate is the carry propagation. We can gain some performance exploiting the facts that a high percentage of die area is required by addition circuits and low number of additions are actually performed so the cumulative error probability can be kept small.
A carry-reduced CLA adder (CR-CLA)
We propose a new type of adder: a Carry-Reduced adder. A carry reduced adder does not propagate the carry from every significant bit to every more significant bit. Propagation longer that a certain length is ignored. When a carry should have been propagated, but was not, we said there was a carry propagation failure (CPF). These failures are expected by design and incorrect results produced by failures must be detected and discarded afterward if they lead to a supposed block solution. An adder that suits well to be carry reduced is the CLA. A typical n-bit CLA consist of the Sigma blocks (which computes the P (propagation) and G (generation) signals) and the Carry Lookahead Generator block (CLG) which computes the n carries. In SHA-256 the last carry is unused and only (n-1) carries are computed. The CR-CLA overall design also mimic this structure, but at least one CLGs is replaced by a carry reduced CLG (CR-CLG). A CR-CLA generates a correct output with high probability if the two are independent random variables, but uses less gates and have less delay than a standard CLA.
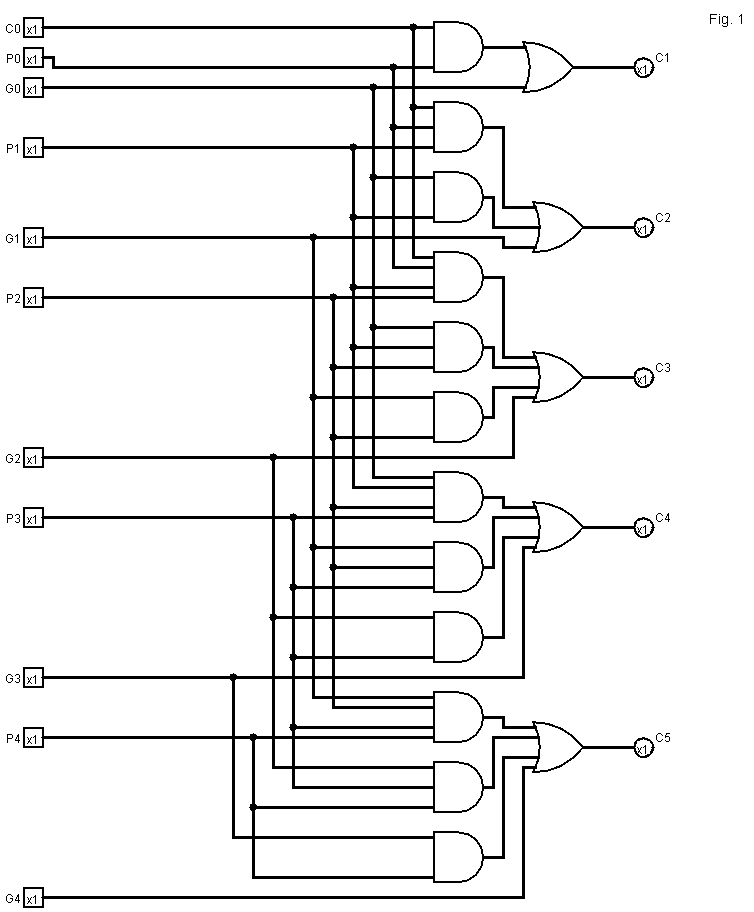
Extensions of the CR-CLA design to hierarchical designs can be naturally created in a similar way of hierarchical CLAs. The CR-CLG block of the CR-CLA adder can be placed at one level and another CR-CLG at higher level. Also a standard CLG can be placed at one level and CR-CLG at higher levels. A (k,n)-CR-CLA adder is a n-bit CLA where the carry at bit c(i) is computed using the propagation (P(j)) and generation (G(j)) signals of the at most k contiguous bits of lower significance adjacent to the bit i, where 0<k<n. The case k=n would be a standard n-bit CLA. The reduction in the number of inputs used to compute each carry (the carry generation logic) allows the saving of logic gates and the reduction of the delay. Figure 1 shows a (4,5) CR-CLA with input carry. Each carry takes into account no more than 4 previous carries.
Carry Propagation Failure
We have defined a carry propagation failure (CPF) as the event where a (k,n)-CR-CLA gives an incorrect value as result compared to the mathematical addition. For n=32, k=13, the CPF probability computed by simulation is 0.027%. For k=16, n=32 and 386 additions, the rate of failure of the whole double SHA-256 core is approximately 2.2%. The reduction in die area by reducing CR-CLG levels should allow more than 2.3% additional cores to be added, and so the resulting chips is more efficient.
Failures in current ASICs
One of the hypothesis I have is that a standard CLA (or mostly any other kind of adder) that is not given enough operation time (a reduction in the clock interval) to adequately propagate the carry signal behaves similar to a CR-CLA to some extent. It could behave better or worse depending on the gate placing, temperature, nearby wires, electromagnetic radiation, wire length, capacitance, load and other factors. For example in a standard 32-bit ripple adder we can assume it will have a delay of 16 gates, instead of 32 gates, and allow a failure rate. If the node technology allows it, we could overclock at 2x a SHA-256 ASIC that uses ripple adders, and get achieve a better mining rate (although I have not tested it nor I recommend anyone to test this with their hardware).
Other adders, such as parallel prefix adders (Ladner-Fischer adder, Kogge-Stone adder, Brent-Kung adder, Han-Carlson adder) could can also be reduced in carry propagation by removing unnecessary dependencies on the associated graph structures but I have not yet attempted to analyze the resulting designs.
Attacks to ASICs using Approximate Adders
Inputs could be chosen specifically to degenerate the adder Z=X+Y and force it to fail: for example if X is 0xFFFFFFFF and Y=0x00000001. That’s the reason why CR-CLA have little use in traditional micro-processing circuits. In Bitcoin, the Bits field and Time fields in the header could be manipulated by an attacker to force a CPF. If this is possible depends of the association of additions in the w[i] := w[i-16] + s0 + w[i-7] + s1 chain as implemented by the ASIC. The ParentBlockHash field alone could (by chance) produce an unavoidable CPF. But since the internal state is randomized by the compressor and message expansion, only some middle rounds (rounds 16 to 31) may be subject to an attack of this kind. The remaining rounds can take advantage of approximate adders, in an round unrolled design. A year ago, when I discovered these optimizations were possible, I imagined that if every manufacturer tried to obtain the fastest possible implementation without taking into account deterministic CPFs, then all mining machines could freeze at a certain point, unable to advance past a certain block. In that case, orphaning that block would be enough to keep mining going smoothly, as long as the problem field is not “time” or “bits”, which cannot be easily manually adjusted. That day I tweeted a bet that the Bitcoin PoW would change in the following 7 years. I shortly withdrew the bet, when I noticed that some rounds could be computed accurately even if the performance was degraded a bit. I still wonder if there are more or better optimizations based on 2nd order approximations (e.g. merging two rounds). I also wonder if optimizations could push manufacturers to create fully approximate chips, forcing a tragedy of the commons where manufacturers do not try to prevent unavoidable CPFs, because they think the remainder mining machines will work to advance past that point, but no machine does.
Last words
I have no idea if a reduced carry design will actually outperform a standard design considering additional factors, such as the availability of optimized off-the-shelf adders compared to a custom adder. However, I estimate that it can actually provide a speedup of about 5%.
Finally it’s interesting that using approximate adders may help Bitcoin SHA-256 SAT solvers to reduce the instance size and so SAT solving for mining may be a bit easier than previously thought (although it’s probably still practically infeasible)
Disclaimer: This post contains a lot of speculation, it does not suggest nor imply any real problem with the Bitcoin PoW algorithm. We’re quite fine with double SHA-256.

#1 by Nicolas T. Courtois on September 4, 2015 - 2:28 pm
>”I found these three papers that may serve as starting points of a SHA-256 ASIC design.”
You should also cite this which develops aspect NOT covered by traditionnal ASIC researchers which are SPECIFIC to bitcoin:
http://arxiv.org/abs/1310.7935
pages 16-24 sections 10-12.
#2 by SDLerner on September 11, 2015 - 9:50 pm
Also there is a huge optimization not covered by your paper. When there is commercial competition, there are secrets..