One of the key elements to measure the health of a blockchain based cryptocurrency is the number of nodes actually storing the blockchain. The blockchain grows normally according to the number of payments per second. But as a cryptocurrency becomes popular, the number of payments per second increases, and the blockchain growth rate also increases. The storage cost then becomes prohibitively high for a number of the users : they leave the network and move to SPV clients or online wallets. As an example, the number of Bitcoin full nodes accepting connections fell from a maximum of approximately 30K down to 7K (as of today). This amount of nodes seems to indicate that the risk that certain part of the blockchain is simultaneously deleted (either maliciously or by chance) from all nodes is still minuscule.
Nevertheless still one important question remains: how many of copies of the blockchain really exists? It can be the case that a many full nodes are sharing a single copy of the blockchain, and those 7K nodes are just an illusion of a few centralized storage facilities.
Can a user verify if peers have a distinct copy of the blockchain and that that copy is intact?
The standard approach is to use a protocol for “Proof of Data Possession” or “Proof of Retrievability”. In a nutshell, those protocols (with varying properties) provide a way to cryptographically check if a data file stored on a remote server is intact using a challenge-response method. Nevertheless these protocols do not provide and assurance that the data is actually locally stored or at least that the data copy is “unique”. A malicious server could pass the challenge to a third party which is actually storing the data and give back the response to the client, performing a Man-in-the-middle attack. The protocol can be improved by making the challenge a one-way-function of the client and server identities plus some some random nonces provided by both of them. Nevertheless this change does not prevent a malicious party from creating thousands of phantom nodes (identified by their IPs), that either point to a single computer or work as proxies to a single centralized computer having a single copy of the data.
Access Time based Challenges
A simple approach is to create a challenge whose response requires the prover to read multiple parts of the stored data file and send a response containing an integrity check of those parts in a short time. The challenger would try to distinguish between a local or remote read access based on known access times of standard hard-disks (seek time and data transfer rate). But these access times vary widely according to the state-of-the-art of technology and cannot be used reliably over time, so this method cannot provide accurate detection. Most importantly this approach cannot distinguish from a single node having 1000 IP addresses and a single copy of the data file from 1000 full nodes across the globe, having a copy each.
To distinguish between different copies, we need a way to tie each blockchain copy to a single IP address, in a way that it’s difficult to respond to a dynamic query of the blockchain for a different IP.
Asymmetric-time functions
An asymmetric-time function is a function that is invertible for a subset of its inputs, but computing the inverse of an element is much slower than evaluating the function on an element. Computing an asymmetric-time function in one of the directions is “practically-slow”. Here “practically-slow” is only defined in relation with the challenge-response time and the state-of-the-art hardware. The term “practically-slow” in this context means that the verifier will easily detect that an asymmetric-time function is executed in the practically-slow direction during challenge-response. Asymmetric-time functions can be built from hash functions, one-way permutations, T-functions and trap-door permutations. Ideally the function should preserve size and generate outputs that cannot be distinguished from a statistically uniform random variable. The idea is that the data file will be transformed by the server using the “practically-slow” direction with a key that references the server identity (usually the network IP), and the data file is stored in the transformed state. An identity-bound asymmetric-time function family is a set of asymmetric-time functions where there is function for each different key. We also require that the transformed file still allow random reads in blocks of a predefined size. We don’t care if the server stores the file in a compressed form as long as it can successfully reconstruct the original file and provide random access.
There are two possible challenge-response protocols to detect local transformed copies: either the challenger computes all the transformed values, hashes them and compares this to a received hash, or the challenger receives the transformed values and apply the inverse function to obtain a set of values, which are compared to the original data blocks. This last method requires more bandwidth to transmit the values, or it requires a that very few values are read from disk and transmitted. Transmitting all the values increases the challenge-response time, so a more relaxed time bound must be chosen. The first method is preferred if the data file is large, or the network bandwidth is low, or the challenger CPU is very fast, while the second is preferred if the file is small, or the network bandwidth is high or the challenger CPU is slow.
The following figure illustrates the scheme, where f() is the slow asymmetric function:
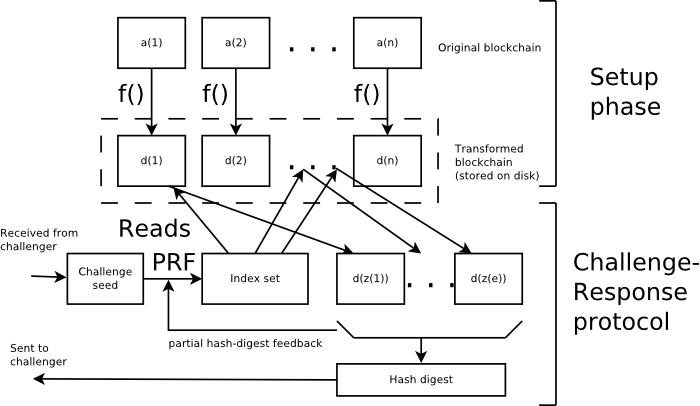
I’ll show two examples of useful asymmetric-time functions.
Asymmetric-time functions: Number-theoretic Asymmetric-time functions
A way of building an asymmetric-time function is by using number-theoretic functions and some related assumptions. It is assumed that current modular exponentiation algorithms are the fastest possible, so there will not be any fundamental improvement in modular exponentiation speed. We describe here one function that relies on the Pohlig-Hellman cipher, which uses modular exponentiation. We define the following constants and functions as a starting point in order to finally present the full construction:
p : a large fixed prime number of m bits length, chosen randomly
H(y) : A cryptographically secure hash function of message y
I : the identity of the server (usually including the IP)
a(1)..a(n) : the untransformed file, divided in fixed-length blocks
PRF(s) : a secure pseudo-random generation function, based on a seed s
f(x) = ( PRF( I ) xor x )^3 (mod p)
f-1(x) = PRF( I ) xor ( x^t) (mod p) , where t = 3^-1 (mod p-1)
First we note that f(x) is bijective for all inputs except zero, which can only appear with negligible probability. Normally the inverse of f will require the exponentiation to a number of approximately m bits in the finite field. So we define d(i) := f-1[a(i)]. It is believed that there is no algorithm to compute a(i) from d(i) in much less time that it takes to do a m-bit exponentiation on average. The “xor” operation is chosen not to commute with modular exponentiation. For a better resistance to any algebraic attack, one can choose f as f(x) = ( E(x,k ) )^3 (mod p), where E(x,k) is the encryption of x under the key k with a fast symmetric cryptosystem.
If m is 1024 bits, then the computation ratio between f and f-1 is approximately 512X. Let’s suppose a 1024-bit exponentiation takes 1 msec on an average PC, and a 2-bit exponentiation (the third power) of a 1024-bit base takes 512 times less. Assume that the round-trip network delay is 100 msec. Suppose that the challenge is a pseudo random seed and the response consist of a hash of a batch of 1000 single-blocks at indexes generated from the seed using a fixed pseudo-random generation function. The response will take 102 milliseconds to be received if the server stores the data file in a transformed format but 1.1 seconds if the blocks must be recomputed on-the-fly.
Regarding the modification of the transformed blockchain, every time a new 1 Mbyte block is appended to the blockchain, the new data must be divided in blocks and each block must be transformed using f-1. Under the same hardware assumptions, this will take 8.1 seconds.
ASIC attack
If a malicious server has a special purpose ASIC capable of computing 1000 modular exponentiations in parallel, the attacker can nevertheless cheat and return the challenge on time. The asymmetric ratio can be increased to 50,000X to prevent such attack. This requires a prime of 51200 bits and adding a new block to the blockchain would take 6.8 minutes of computing time (still less than the average 10 minute block arrival interval in Bitcoin). This also means that the challenge computation for verifying 1000 indexes requires almost 100 msec.
A better protection is to to derive the next block index using the information obtained from the previous block read. We define PRF(s,x) as a preudo random function with initial seed s, but that also depends on a tweak x. Let z(1)..z(e) be the index list. We set z(j) = d(PRF(s,q(i) mod n)), and q(i)=Hash (d(1)..d(z(j-1)). q(j) is the partial hash digest of all blocks up to index j-1. Now an attacker cannot parallelize f-1(), but nevertheless he can still parallelize many concurrent executions of the challenge-response protocol for different verifiers.
Asymmetric-time functions: Mixing non-linear T-functions made of algebraic operations with rotations
A way to achieve an asymmetric function is by building a one-way permutation. One way to build one-way permutations is mixing invertible, non-algebraic and non-linear T-functions that can be computed using arithmetic and logical instructions. For example, let T(x) = x + (x^2 v 5) is a T-function. Let w be the word size in bits. Since modern CPUs have a FSQRT instruction, this T-function asymmetric ratio is approximately 10, which is not very good. For T(x) = x xor (x^2 v 1), there is no algebraic expression of the inverse and I estimate that the asymmetry ratio of at least 32(w-32)/3 if w>=64. This is because there is little room for precomputation of the most significant 32 bits when w>=64, and computing each bit inverse of the 32 most significant bits require at least reading 32 bits less-significant bits. For w=64, we have a ratio of 341. But since this is crucial to the security of the scheme, this ratio must be carefully studied, which I won’t attempt here. A careful analysis should try to estimate the boolean circuit complexity of f-1. Suppose that we define two T functions T(0) and T(1) which have an asymmetry ratio of 341, and a circular byte rotation function R.
If the server identity expressed as a sequence of bits is B(i) then we recursively define the function r(0) = identity, r(i) = R(T(B(i))) o f(i-1), where “o” is the function composition. If the server identity is 20 bytes long, then one can create function with an asymmetry ratio of 54,000X by defining f(x) = r(160)(x). The function f defined is a identity-bound bijective asymmetric-time function. As an example, if computing f(x) in an actual PC requires 100 ns, then inverting an element would take about 5 seconds. Note that the word can never be shorter than 64 bits to prevent an attacker from pre-computing the inverse of T(0) and T(1).
Also MDS matrices (optimal invertible linear mapping of diffusion) may be used to build Asymmetric-time functions.
Summary
A data file (e.g. the blockchain) is asymmetrically transformed using an unique server identity prior storage and any other proof of retrievability is used to provide proof of possession of the transformed file. Using this method, a node can verify that a remote node has a unique copy of a data file over the Internet.
Some other important questions remain: how many hard-drives are actually storing those many copies. It could be the case that most copies are stored in very few storage devices or in a single data center. This means that the risk of data destruction because of a natural disaster may be high. Can we prove that two representations of a single data file are stored in two geographically distant places? Performing two parallel but local challenge-response Proof-of-Local-storage protocol runs, where transfer latency is required to be less than a few milliseconds, it may be possible.

#1 by Craig S Wright on December 8, 2014 - 4:00 am
The HDD assumption is flawed to start. I would start with Ram. The reason to do such an attach needs to be incorporated into the equation and hence the cost benefit of such. This is unlikely to be an attack make from a home user or small scale malicious bot.
Next, latency can be reduced even over distance. There are sites close by that are slower than access we hold to NY from Australia.
The analysis is only as good as the assumptions and they have flaws.
The systems we run are measured in sub-microsecond latency. Without an ASIC, we can still simulate this.
There are also extended instruction sets that will deal with this in memory.
#2 by SDLerner on December 9, 2014 - 5:45 am
There is no such HDD assumption here. On the contrary, I propose a method that can be made secure even if you could transmit data from Sidney to Buenos Aires without delay. The method relies on a CPU-speed limit that you can tune in practice such that either you spend X dollars in storage, or you’ll need to spend Y > X dollars in a faster CPU. And for data that is appended not very frequently, then Y can be made orders of magnitude higher. So if you pass the challenge-response test the protocol cannot prove you are storing the data, but proves that you’ll be an idiot not to store it.
#3 by Craig S Wright on December 9, 2014 - 5:55 am
“So if you pass the challenge-response test the protocol cannot prove you are storing the data, but proves that you’ll be an idiot not to store it.”
No, not if you have a reason not to stare it.
#4 by Craig S Wright on December 9, 2014 - 5:57 am
“The method relies on a CPU-speed limit that you can tune in practice such that either you spend X dollars in storage, or you’ll need to spend Y > X dollars in a faster CPU. ”
And no, I can parallelise these tasks to bypass this.
I do not need to have an IP tided to a copy, I can still have a single copy and many IPs.
#5 by Iggy S. on August 23, 2015 - 8:32 pm
“Nevertheless this change does not prevent a malicious party from creating thousands of phantom nodes (identified by their IPs), that either point to a single computer or work as proxies to a single centralized computer having a single copy of the data.”
Correct me if I’m wrong, but that makes it completely useless doesn’t it? That attack is trivial, so… basically this proof doesn’t… prove?
#6 by SDLerner on September 3, 2015 - 6:38 pm
If you continue reading you’ll see how using asymmetric-time functions this problem is solved.