These days I saw some reawaken interest in searching for pattern s in early mined blocks by Taras. Well, last month media circus around Dorian Satoshi may have contributed. I welcome Taras to the chain-archeology field, and I hope he does it responsibly.
s in early mined blocks by Taras. Well, last month media circus around Dorian Satoshi may have contributed. I welcome Taras to the chain-archeology field, and I hope he does it responsibly.
While reading his posts I remembered two chain-archeology techniques [1] that I planned to test, but never did in depth. One is Re-mining, the other is Lucky Pairing. Last, I give a clue that suggest that Satoshi’s mining machine was a standard (state-of-the-art) PC.
Re-Mining
Re-mining is like replaying the past mining history to see if what happened was actually the most probable outcome when taking certain assumptions. Seems like a a sci-fi plot, doesn’t it? Instead, it is something very concrete: re-mining means searching for solutions (hash digests below target) for blocks that have already been solved. You can re-scan all the nonce space for certain block headers and see if there are other solutions apart from the solution found.[2]
Since the difficulty of the first 30K blocks is very low, a single GPU can fully re-mine them all in a very short time (probably a single day).
With a standard CPU I re-mined only the first 1K blocks or so and still I found some evidence of a very interesting fact: the Satoshi nonce LSB range has not higher probability of success over the unused LSB range. The number of solutions you’ll find out of the Satoshi LSB range are (statistically) the expected number of solutions with great confidence. This means that Satoshi did not have a magic (or mathematic) way to breaking SHA-256 by choosing nonces in the LSB range he used. In other words, the range seems not to have been chosen to improve the chances of success (although it still possible that an optimized technique he may have used may only yielded solutions in that range)
I tried to discover if Satoshi was incrementing the nonce or decrementing the nonce while counting: if many more solutions are found with nonces higher than the actual nonce found by Satoshi than below it, then he was probably incrementing as the standard client does (if not he would have found the higher solution first with high probability). If it is the opposite, then he was decrementing. If neither of them, then he was doing something completely different, such as pseudo-randomly changing bits, or counting using a gray code or who knows what. Note that for testing this hypothesis, not all the nonce space should be re-mined: the 0.1 client changed the nTime field when block.nNonce & 0x3ffff == 0. This should have occurred about every 1/16 of a second. So research should focus on re-mining the 0x4000*50/256=51200 nonces that corresponds to the range of the found solution and the Satoshi LSB range. With probability about 1/16384 there will be another solution in that range. This other solution will be higher or lower. I tried this over the first 50K blocks, but I couldn’t find any other solution, neither higher nor lower. To get some statistically significant result, I suppose one must collect at least 10 pairs, so about 160K blocks should need to be re-mined.
Lucky Pairing
In another attempt to discover more about Satoshi hardware, I scanned all pair of Satoshi blocks where the extraNonce of the second block is one unit higher that the extraNonce of the first block. Since the extraNonce is incremented each time a new block is prepared to be solved, the minimum possible extraNonce difference is 1. Then I filtered the pairs where they were as close as possible temporally using the nTime field, e.g. 250 seconds apart. Since the nonce rolled about 5 times in 10 minutes because of the Satoshi LSB restriction, then one can expect than it should not roll if the time difference is less than 2 minutes. My intention was to count the number of times the nonce value of the second block was higher than the nonce value of the first block, and the number of times it was lower. But there were no enough pairs with time difference under 2 minutes as I would have expected. This is odd. One explanation is that the Satoshi miner, after a block was solved, waited some time until the remaining “threads” that were still processing the previous block finished computing, without automatically killing these threads, or flagging them to stop. This would also imply that the Satoshi miner was not very optimized.
Since one needs a GPU and free time to do this research, and I have none of them, I hope someone with a great curiosity will research on this. If you do, please send me the raw data!
Why Satoshi’s mining machine was probably a PC
One interesting thing that happens to the Satoshi pattern can bee seen here:
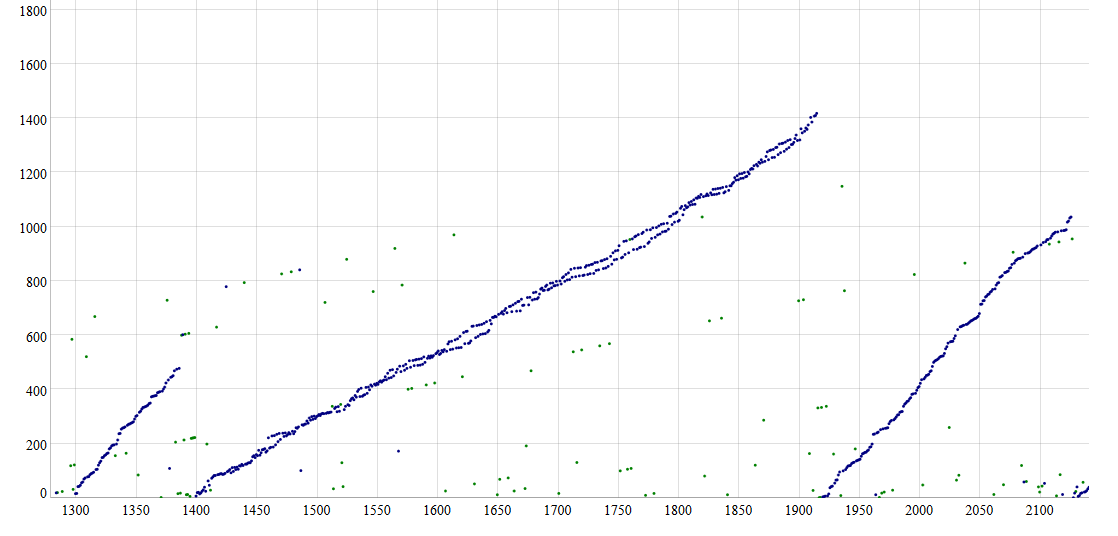
Blocks 1300-2100
From block 1400 to block 1900 Satoshi launched two instances of his mining application instead of one. This could have been simply a mistake. We can see that the performance of each application is reduced, because the threads in both applications are competing for the same cores. This implies that Satoshi’s computer was probably quad-core, and not more.
We can rule out that the nonce LSB was used to identify different mining devices or computers, since both paths in the double pattern use the full range of Satoshi LBSs. It was probably used to identify different mining threads.
(To compare the performance of the single and double Satoshi patterns, one have to take into account that extraNonces also increment with every block solved and not just the time passed.)
Happy responsible chain-archeology!
[1] I really don’t remember if I came up with the idea myself or Timo Hanke suggested it to me.
[2] Also you can scan the “unused” space between extraNonces by changing the extraNonce field, recomputing the generation transaction hash, and rebuilding the Merkle-tree to match the supposedly checked block header in the past, and then do the nonce scan. But the standard 0.1 changed the block.nTime field periodically, so it would be hard detect which blocks where the ones actually checked by Satoshi. But a discovery is there to be made: if it is found that, fixing the time as the same as the next found block, the blocks with skipped extraNonce values do not have additional solutions, then it will be the case that the special client used did not change the nTime field as the standard 0.1 client did.
